Fail-to-Learn: A Resolution Mechanic
Let’s say you have a skill with rank , starting at . To test the skill, roll a d% and compare:
- If you roll under or equal to , you succeed.
- If you roll over or equal to , you learn. When you learn, increase by .
- Naturally, if you roll exactly equal to , you succeed and you learn.
This is substantially similar to the core mechanic of Penny Spent, but broader.
I am naming this Fail-to-Learn. Initially, I had intended to submit this as my 2024 New Year’s Resolution Mechanic, but I got distracted and made clashing instead.
The Math of Fail-to-Learn
The First Success
Obviously the first test of a skill will fail; the minimum roll of a d% is 1 and we need 0 or lower. But every failure improves the odds of future success. How many tests () should we expect before1 the first success? This is a geometric-ish distribution:
We can plot the probability of a given test being the first success like so:
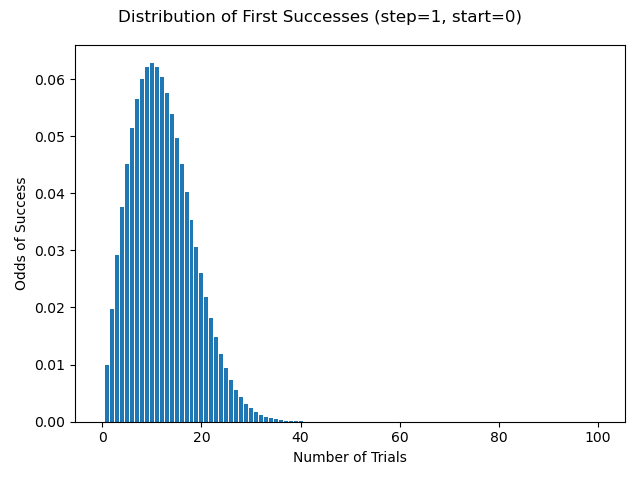
And we can extract the most likely candidate by finding the maximum of this plot (, so the 11th trial).
What if we want to start with 5 ranks in a skill () or we think learning should increase 3 ranks at a time? We can tweak the above formula to be:Or, as a recurrence:
Where is the increment of learning and is the initial skill rank. We can find the maxima of a range of similar rules:

But really, most of the detail there is in the upper-left corner, so let’s take a closer look at that:
 The unlabeled regions are zero.
The unlabeled regions are zero.
Suppose I want to know specifically about Penny Spent. Rather than generalize to other die sizes, we can pick the rule (because I am lazy). Looking at the detail plot, this gives us a most likely first success of the 5th trial.
But this can be misleading. Suppose it is most likely to succeed with one or zero preceding trials. It can still be unlikely to succeed in those circumstances, it’s just more likely than with any specific larger number of trials. To illustrate this, I pulled two distributions that are most likely to succeed with zero and one preceding trials, respectively.

The Last Failure
How many tests will it take to “max out” a skill () such that you never fail that test again? We can start by showing how each test changes the state (or rank, ) of the skill.

But this is familiar! This looks like another absorbing Markov process. So while our transition matrix will look a little different, we can deploy the same strategies here.
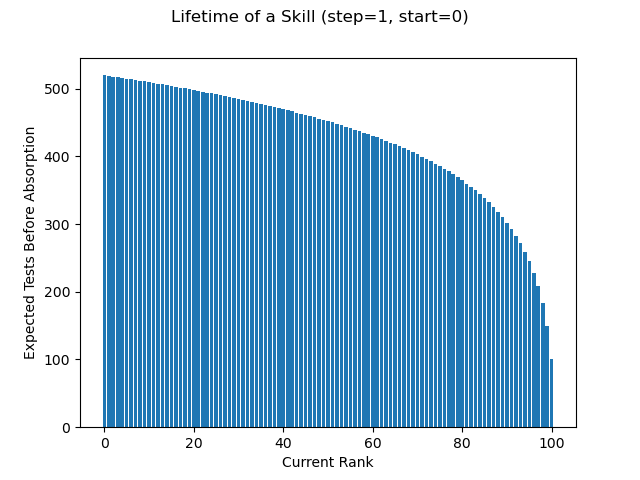
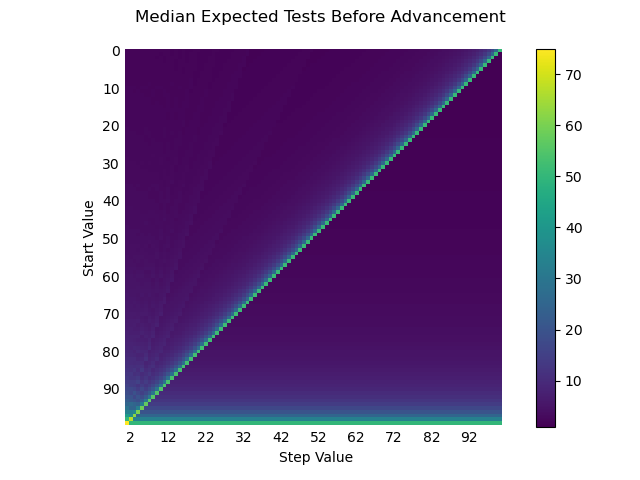
Doing so shows us that for our initial mechanic, you should expect ~520 tests before “saturation” (). But wait! You can’t fail at any more than at . And really, you’re mostly maxed out at . But if you’re effectively maxed out at , what’s the real difference between that and … We can solve instead for the expected number of tests between consecutive ranks and plot them like so:
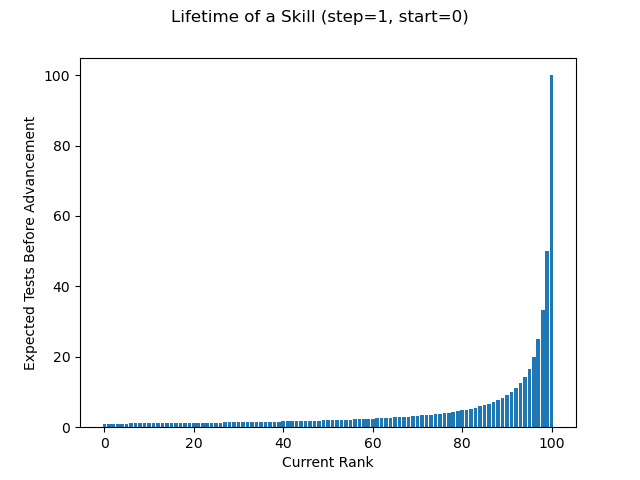
The median number of tests between advancement here is only ~2, which we should expect to be the case for the bulk of the time the skill is relevant (e.g. excluding first and last tests).
Selecting a Better Mechanic
Having here played around with and before played around with , perhaps a more “tuned” mechanic can be selected. To this end, I created heatmaps of tests before saturation and median tests between advancement, before wandering away from this idea.
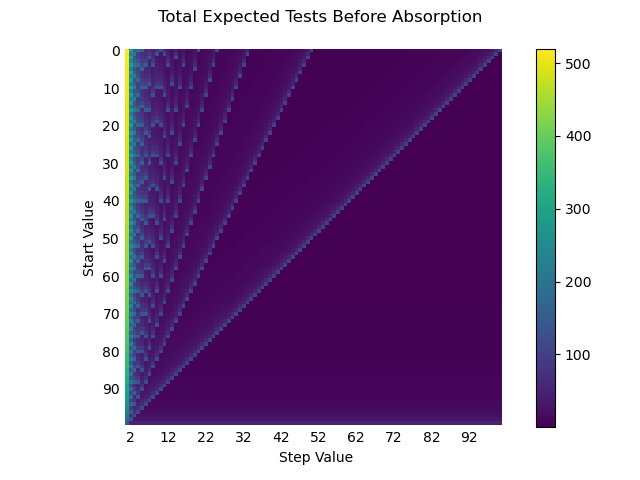
Implementation Notes (Game)
Fail-to-Learn suffers from being a mechanic where testing is always advantageous. In practice, vague advice like “only test when there is a risk of failure” or “testing must involve some risk” will be forgotten or applied unevenly. Therefore, I suggest that not only should tests carry some cost, but that cost should be consistent. The easiest cost here is time. In Penny Spent, testing takes a whole watch. But it could be an expenditure of resources or a risk of some constant threat, so long as it is sufficiently “game-like” in application.
Then this mechanic limits its own scope: if testing takes a whole watch, what am I to do when I need to break down a door right now? Or if I am out of metacurrency, how am I to accomplish anything at all? Fail-to-Learn seeks a complementary mechanic for these situations, perhaps something with no upside to failure and quicker to compute, like comparison to a static difficulty number.
That said, I think Fail-to-Learn is a flexible mechanic, easy to tweak and tune. Maybe you can find a good home for it! Maybe it already has one!
Implementation Notes (Code)
As always, the code used to do this math and generate these images is available in a gist.
This wording is particular. On the first trial, there will have been attempts preceding it. This makes the math easier, as long as we remember to add the 1 back in after.↩︎